
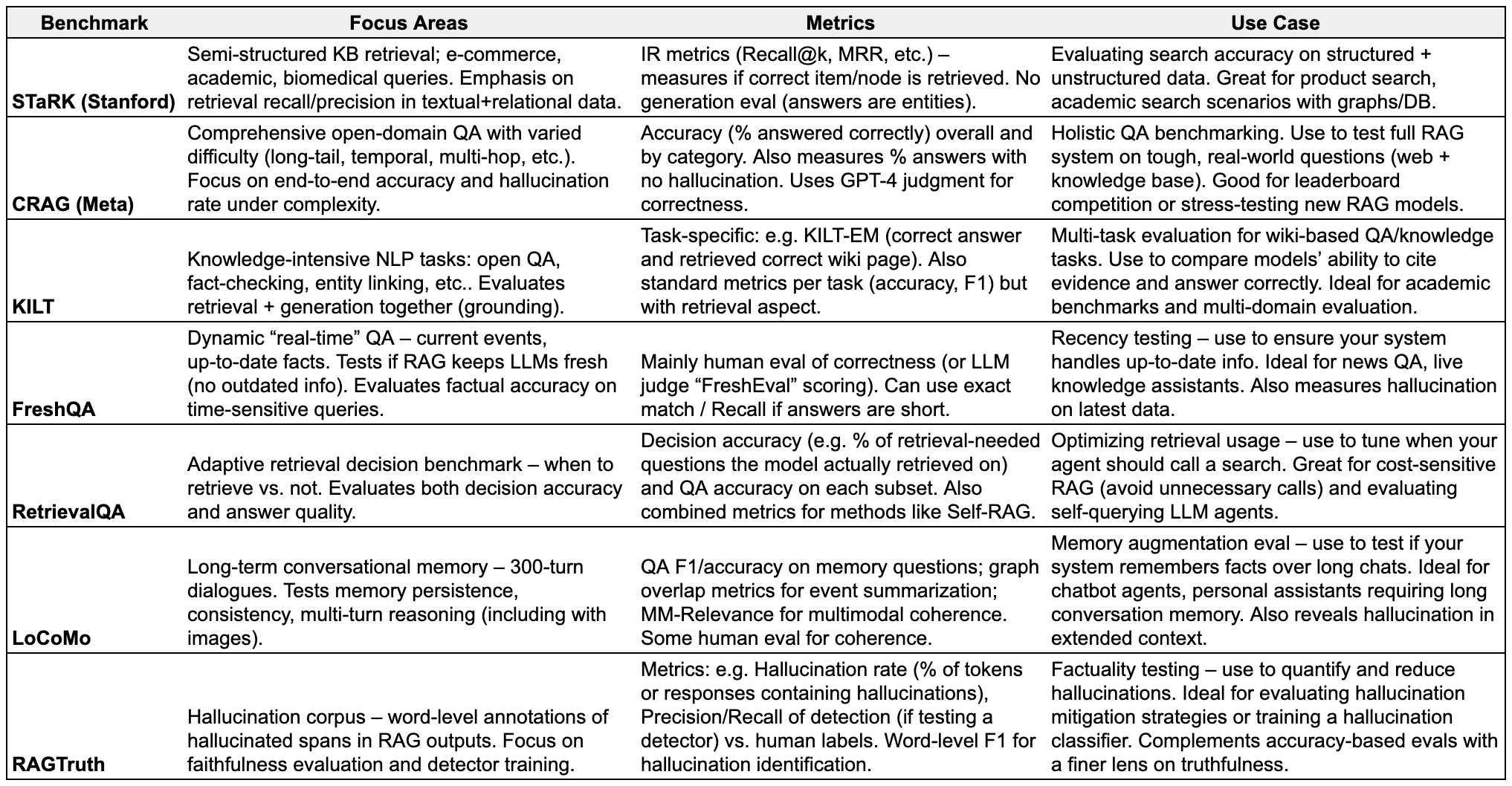
Benchmarking Retrieval-Augmented Generation (RAG) Systems
The definitive playbook for evaluating retrieval-augmented LLMs

Evaluating RAG systems is challenging because it involves assessing both the retrieval component (are relevant documents fetched?) and the generation component (are responses correct and grounded in those documents). Below we survey major open-source benchmarks and frameworks for RAG evaluation. We outline what each evaluates (faithfulness, hallucination, retrieval recall, QA accuracy, long-term memory, adaptive retrieval decisions, etc.), the format (datasets, metrics, leaderboards, tasks), whether code/tooling is provided, and pros/cons with recommended use cases.
Benchmarks & Datasets for RAG Evaluation
These benchmarks provide datasets and tasks to evaluate RAG systems in various scenarios. They typically include queries (and sometimes ground-truth documents/answers) to test retrieval and generation.
Stanford STaRK - Semi-Structured Knowledge Base Retrieval
What it is: A large-scale benchmark for LLM-driven retrieval on semi-structured knowledge bases. It covers three domains: product search, academic paper search, and biomedical inquiries. Queries combine unstructured text with structured constraints (e.g. attributes or relations). Ground-truth answers are entities (nodes) in a semi-structured KB. As of this writing papr.ai is ranked 1st on Stanford’s STARK benchmark - MAG 10% sample.
What it evaluates: Retrieval accuracy in scenarios where relevant information is spread across text and relational data. It tests an LLM+retriever’s ability to handle queries that require understanding both free text and structured relations. The focus is on retrieving the correct entities from the KB (to then answer the query). This stresses precision and recall of the retriever, and the ability to use structured cues (like graphs or tables) along with text.
Format & Data: Three sub-datasets: STaRK-Amazon (e-commerce products), STaRK-MAG (academic publications), STaRK-Prime (biomedical research). Queries are natural language but synthesized to include realistic constraints (e.g. “Looking for durable Dart World brand dart flights…” with answer being specific product names). Each query comes with verified ground-truth entity answers. The benchmark provides a Hugging Face leaderboard for model submissions. Metrics include typical IR metrics like Recall@K, Precision@K, or MRR – e.g. how often the correct node appears in top results.
Tooling: Code available (Stanford’s GitHub) including data loaders and evaluation scripts. The HF leaderboard integration means you can evaluate your system’s output easily against ground truth.
Pros: Unique in combining text and knowledge graph-style evaluation; reflects practical queries (e.g. complex product filters, academic citations) that pure text QA benchmarks miss. It is large-scale and diverse, providing a realistic stress-test for retrieval. Great for enterprise KB QA or any domain where structured data is involved.
Cons: Focused just on retrieval accuracy of entities – not an end-to-end QA metric. It “skips the step of extracting info from real documents” (answers are entities, not full text) as one reviewer noted. So it doesn’t directly evaluate generated answer correctness or fluent synthesis, only the retrieval part. Also, queries are partly synthetic (though validated by humans).
Use when: Your use-case involves searching semi-structured data (product catalogs, scholarly databases, medical ontologies). Use STaRK to benchmark retriever configurations or LLM+retrieval prompts in those settings. If your system needs to find the right item or record among many (rather than produce a free-form paragraph answer), STaRK is highly relevant for measuring retrieval quality.
Meta CRAG – Comprehensive RAG QA Benchmark
What it is: A factual question-answering benchmark from Meta AI, designed to capture the diverse and dynamic nature of real-world QA tasks. CRAG stands for Comprehensive RAG Benchmark. It consists of 4,409 QA pairs covering 5 domains (Finance, Sports, Music, Movies, and Open-domain) and 8 question categories (e.g. multi-hop reasoning, comparative questions, false-premise questions). Crucially, it provides “mock retrieval APIs”: a simulated web search (with 5 or 50 HTML pages per question) and a large Knowledge Graph, which models the retrieval sources.
What it evaluates: End-to-end QA accuracy under challenging conditions. CRAG tests whether RAG systems can find correct answers in a variety of scenarios: popular vs long-tail entities, static facts vs time-sensitive facts, single-hop vs multi-hop reasoning, even cases with misleading or false premises. It emphasizes both correctness and avoidance of hallucinations. For example, in CRAG’s initial evaluation, even GPT-4 level LLMs answered only ≤34% of questions correctly without retrieval, and a basic RAG approach got ~44%. Top RAG pipelines (from a KDD Cup challenge) could answer ~63% without hallucination – highlighting how far from 100% current systems are.
Format & Data: Each question comes with a set of documents (HTML pages) and/or access to a KB, simulating what a retrieval module would find. Systems are expected to retrieve relevant info and generate an answer. Automatic evaluation is done by comparing the generated answer to the ground-truth answer. CRAG uses an LM-based evaluator (GPT-4) to judge answer correctness against the reference, since some questions require nuanced or aggregated answers. (The benchmark also had a human-curated ground truth for each question). CRAG was the basis of KDD Cup 2024, so it has an active leaderboard and evaluation scripts. Code and data are available on GitHub (the authors commit to maintaining it as a community resource).
Pros: Very comprehensive – covers multiple domains and question types in one benchmark. It explicitly tests for weaknesses like temporal queries (answers change over time), obscure knowledge, and complex reasoning, making it a holistic stress test for RAG. The inclusion of both web docs and a structured knowledge graph is novel, allowing evaluation of systems that combine text and structured retrieval. There’s a ready-to-use evaluation harness (from the KDD Cup) and participants’ solutions/metrics to compare against.
Cons: The dataset size (4.4k questions) is moderate – larger than many QA sets but smaller than some web QA datasets. Also, evaluating via an LLM judge means you rely on that judge’s correctness; however, the metrics were carefully validated. Another consideration is that CRAG’s format (with provided documents) assumes you use their corpus – if your system’s knowledge source differs, you’d need to adapt it to use CRAG’s provided docs/KG for a fair evaluation.
Use when: You want a standardized, rigorous QA benchmark to compare RAG approaches, especially to see how your system handles real-world complexity (long-tail queries, time-critical info, etc.). CRAG is great for leaderboard-style evaluation of complete RAG systems. Use it to identify if your system’s weakness is in retrieval (failing on certain domains or multi-hop) or generation (hallucinating or failing on tricky questions), since the results by category can pinpoint that.
KILT – Knowledge-Intensive Language Tasks Benchmark
What it is: A benchmark (from Facebook AI, 2021) consisting of 11 datasets for various knowledge-intensive NLP tasks. All tasks are grounded in a single snapshot of Wikipedia as the knowledge source. KILT includes open-domain QA (e.g. NaturalQuestions, TriviaQA), fact verification (FEVER), slot filling (T-REx), entity linking (wiki linking tasks), and dialogue (Wizard-of-Wikipedia). The idea is a one-stop benchmark to evaluate how well systems can retrieve relevant Wikipedia info and use it to produce correct outputs across different tasks.
What it evaluates: Both the retrieval and generation quality for knowledge-intensive tasks. KILT introduced a unified metric: for example, in open QA, a system is only fully correct if it retrieves the correct Wikipedia page and produces the correct answer from it. This combined metric (often called KILT-Accuracy) rewards proper grounding. For fact verification, the system must retrieve evidence and make the correct true/false judgment. So KILT stresses factual accuracy and proper citation to the knowledge source.
Format & Data: Each task in KILT comes in a unified JSON format with a query, possibly an initial context, and ground-truth answers + reference Wikipedia pages. The knowledge source is a fixed Wikipedia dump (2019), so retrieval results are expected to reference pages by ID. There is an online leaderboard (hosted originally on EvalAI) and an official evaluation script that checks if the predicted Wikipedia page and answer match the ground truth. Metrics vary by task: for QA it’s exact match of answer plus a check on retrieval, for entity linking it’s accuracy of the linked page, etc.
Tooling: Yes, a KILT library was released to help with evaluation and to wrap existing systems. Many baseline models (retriever + reader pipelines, and early RAG models) were evaluated on KILT, providing reference scores.
Pros: Broad coverage – one benchmark spans many tasks (QA, verification, etc.), so you can test general-purpose RAG systems across them. It encouraged standardized evaluation of retrieval-augmented models, and it’s useful for multi-task systems. If your system uses Wikipedia as a knowledge source, KILT is very directly applicable with minimal setup. It’s also good for comparing against pre-LLM baselines (like DPR or RAG model from 2020) in literature.
Cons: The Wikipedia snapshot is from 2019, so it’s static and a bit outdated – not ideal for evaluating handling of current knowledge. Also, today’s large LMs know many answers internally, so a naive LLM might do well on KILT QA without retrieval (because the questions are from existing datasets). This can muddy evaluation of retrieval: e.g., GPT-4 could answer many KILT questions correctly from parametric memory. In other words, KILT might underestimate the value of retrieval for state-of-the-art models, since they were not designed with powerful LLMs in mind. Additionally, KILT’s combined metric can be harsh; it doesn’t give partial credit if you retrieve the right document but slightly miss the answer.
Use when: You need a benchmark suite for knowledge-intensive tasks on a common knowledge source. It’s great for academic comparisons and ablation studies (retriever or reader improvements) on standardized tasks. If you have a new retrieval algorithm or a new RAG model and want to show it improves factuality or evidence usage on known tasks like NQ or FEVER, KILT is the go-to. It’s also useful if your application is Wikipedia-based QA or you want to fine-tune models with a built-in evaluation set. For modern systems, use KILT primarily to check evidence citation and grounding rather than raw accuracy (since LLMs may already be super-human on raw answers for some of these tasks).
FreshQA (FreshLLMs) – Dynamic “Fresh” Knowledge QA
What it is: A dynamic question answering benchmark introduced in 2023 to evaluate how well LLMs can handle up-to-date, evolving information. FreshQA collects questions that cannot be answered by static knowledge because they depend on recent events or information that changes over time. For example, news events, current facts (“Who is the current CEO of X?”), and so on. The initial dataset has 600 natural questions, and importantly, FreshQA is continuously updated (the maintainers add new questions weekly). This makes it a living benchmark that tracks whether an LLM+retriever stays current.
What it evaluates: Primarily factual correctness on time-sensitive or “fresh” queries, and by extension the effectiveness of the retrieval component in providing up-to-date information. It directly evaluates hallucination vs. correctness in scenarios where an LLM alone (with training cutoff) would otherwise be outdated. FreshQA is often used with human evaluation: the authors argue human raters are best for judging factuality and catching subtle errors. They also provide an automatic metric called FreshEval – an LLM-based evaluator (few-shot GPT-4) to judge an answer’s correctness against the latest reference. So evaluation focuses on factual accuracy and whether the model’s sources truly support the answer (no made-up info).
Format & Data: Questions cover a range of topics (news, sports, “new world knowledge” etc.). For each question, they provide the up-to-date answer (as of that week) and reference source URLs. The dataset is hosted as Google Sheets and JSON, updated weekly. There are 600 questions in the original publication; by now (2025) many more have been added through the weekly updates. To evaluate, you run your RAG system to answer these questions using a live search or recent index, then compare answers to the provided ground truth. The authors used human evaluation of correctness (and also report a “FreshQA recall” – percentage of answers containing the ground-truth answer). Automatic metrics like exact match are less meaningful here due to open-ended answers, so LLM-based scoring (FreshEval) or human judgment is used. Code is provided (in the FreshQA GitHub) to run their FreshEval evaluator and example notebooks.
Pros: Directly tests the core promise of RAG: staying up-to-date. This is one of the few benchmarks that requires retrieval (a frozen model alone will fail), so it’s excellent for highlighting the value of retrieval augmentation. It’s continuously updated, so you can keep re-evaluating on new questions (even use it as a weekly regression test for your production QA system against latest news). FreshQA comes with an open-source toolkit – they include evaluation notebooks, the FreshEval LLM judge (which reportedly correlates well with humans), and even a “FreshPrompt” for prompting LLMs to use retrieval.
Cons: The questions, while real, are aggregated by researchers, so they may not cover all domains equally (heavy on news and trivia). Since it relies on external up-to-date data, running the eval can be complex – you might need access to a search API or a constantly refreshed index. Also, because it’s dynamic, there’s no single “leaderboard” number; performance can degrade as time passes if your system isn’t updated. In terms of size, even with updates it’s not extremely large – each weekly batch might be a few dozen questions – so statistical significance can be iffy. You’ll likely use it in tandem with other evaluations.
Use when: Keeping current is important – e.g., you’re building a chatbot that answers questions about recent events, finance, etc. FreshQA is ideal to ensure your RAG system actually improves on an up-to-date QA task. Use it to compare LLMs with vs. without retrieval on current questions (it will show a large gap, proving RAG’s worth). Also use it to measure hallucination rates on current facts – FreshQA’s human eval setup can quantify if your model is guessing outdated info. In short, FreshQA is a must for any RAG scenario where the knowledge cutoff of the base model is a concern.
RetrievalQA (Adaptive Retrieval Decision Benchmark)
What it is: A dataset introduced in 2024 (Findings of ACL 2024) to evaluate when a model should invoke retrieval versus rely on its own knowledge. It contains 2,785 open-domain questions partitioned into two types: (1) those that require external knowledge (“new world” or niche questions) and (2) those that can be answered from parametric memory (common knowledge). Roughly 45% need retrieval and 55% do not. The dataset sources include FreshQA and RealTimeQA for the “new” questions, and things like TriviaQA/PopQA for the “known” questions. The goal is to test adaptive RAG: systems that decide on the fly whether to use retrieval for a given query.
What it evaluates: Two things: retrieval decision accuracy (does the system correctly choose to retrieve or not?) and overall QA accuracy. A good system should retrieve for the 1,271 “needs retrieval” questions and not retrieve (just answer directly) for the 1,514 “answerable from parametric knowledge” questions. Metrics include accuracy on each subset, and a special focus on the “adaptive retrieval accuracy” – essentially, did the system avoid unnecessary retrieval while still answering correctly. The authors propose methods like a threshold on model confidence (Self-RAG) and evaluate how well those methods perform. So, this benchmark shines light on efficiency and smart usage of retrieval (important for latency/cost optimization).
Format & Data: Provided as a JSONL file with each question, its answer, and a flag indicating if it requires retrieval (param_knowledge_answerable: 0 or 1 in the data). For convenience, they also supply a set of pre-retrieved documents for each question (so one can test generation separately from retrieval). The “context” field includes candidate passages, some of which contain the answer. This is helpful to isolate the decision problem (you can assume if retrieval is invoked, these docs are what you’d get). Code is available for reproducing experiments, including baseline LLM prompts, retrieval using SERP API for live queries, etc. They also include an implementation of Self-RAG (a method where the LLM generates a special token to decide to retrieve).
Pros: This is a very practical benchmark – in real-world deployments, unnecessarily calling a vector DB or web search for every query is inefficient, yet missing a needed retrieval leads to errors. RetrievalQA quantifies how well your system balances that. It’s relatively small and easy to run. The inclusion of pre-retrieved context means you can test your generator’s ability to choose the right info assuming retrieval was done, separately from the decision policy. Good for evaluating agent-like behavior (to retrieve or not) and for cost-sensitive RAG.
Cons: The dataset is not huge, so measure variance accordingly. Also, the “ground truth” of which questions truly need retrieval comes from the authors’ classification using certain sources; it’s possible a strong LLM might answer a “needs retrieval” question correctly without retrieval occasionally (just by luck or hidden knowledge), but the benchmark would count that as an error in decision (since it expects retrieval). However, this is minor. Another con: it currently focuses on short-form QA only – not other tasks – so the scope is narrow.
Use when: You are concerned with RAG efficiency or dynamic retrieval. If you’re developing an LLM agent that should call a tool only when needed (e.g. decide to do a web search), this is an ideal test set to tune that decision logic. Also use it to compare different strategies: e.g., prompt-based (LLM decides with a special token) vs. confidence-based vs. always-retrieve vs. never-retrieve – RetrievalQA provides a clear success metric for these strategies (the closer your accuracy gets to a hypothetical oracle that knows which questions need facts, the better). In summary, use RetrievalQA to ensure your system retrieves when it should, and only when it should.
LoCoMo – Long Conversational Memory Benchmark
What it is: LoCoMo (Long Conversation Memory) is a benchmark from 2024 for evaluating LLM-based agents on very long-term conversations. It comprises a set of 10 extremely long conversations (300 turns, spanning 35 chat sessions each) between two simulated agents, enriched with events and even images. Think of it as a test of an AI agent’s memory persistence and consistency over a lengthy, evolving dialogue. Based on these conversations, LoCoMo defines three evaluation tasks: Question Answering about earlier dialogue content, Event Summarization (reconstructing a timeline of events from the convo), and Multimodal Dialogue continuation (the agents discuss images as well, and the model must stay consistent with past discussion). Some questions require reasoning across multiple sessions or recalling facts mentioned hundreds of turns ago.
What it evaluates: The focus is on long-term memory and consistency. For QA, it checks if the model can correctly “recall” or fetch information from far back in the conversation (testing retrieval from long context or an external memory). For summarization, it evaluates understanding of causal and temporal connections in the dialogue. For multimodal generation, it checks if the model’s responses remain coherent given an image and a long dialogue history. Essentially, LoCoMo is evaluating how well a RAG system (or any memory mechanism) can preserve and utilize knowledge over a prolonged interaction. Metrics used include standard QA metrics (F1 for QA answers), possibly ROUGE/BLEU or human eval for summarizations, and a custom metric (MM-Relevance) for multimodal consistency. The authors report how vanilla LLMs, long-context LLMs, and retrieval-augmented LLMs compare. For example, RAG-based approaches significantly improved QA accuracy (22–66% better than baseline) but still were far below human-level, especially on temporal reasoning. Also, long-context models hallucinated significantly in adversarial questions, whereas RAG was more grounded. This indicates LoCoMo is good at highlighting hallucination and context-loss issues over long dialogues.
Format & Data: The dataset (LoCoMo conversations) and the evaluation scripts are available (Snap Research GitHub). Each conversation is a structured JSON with turns, speakers, etc. The QA task provides question prompts (with reference answers for evaluation). The summarization task provides an “event graph” for each agent as ground truth, and expects the model to produce something that can be compared to that graph. For multimodal, there are ground-truth dialogues. Automatic evaluation for QA is straightforward (F1/EM against ground truth answers). Summarization and multi-modal dialogue may rely on some match metrics or human judgment of consistency. The authors also released LoCoMo-MC (multiple-choice questions derived from LoCoMo, 1,986 items on HuggingFace) to simplify evaluation of memory recall via multiple-choice.
Pros: LoCoMo addresses a critical but often overlooked aspect: long-term interactions. It’s great to evaluate RAG systems that are supposed to function as conversational agents or personal assistants over time, where knowledge should accumulate. If your system uses a retrieval-based memory (e.g. storing past dialogue chunks in a vector DB), this benchmark will tell you how well that approach works versus alternatives. It’s also multimodal, adding an extra challenge relevant for assistants that see images. The benchmark is high-quality: conversations were generated by LLM agents following personas and then cleaned by human annotators, so they are realistic and consistent. The tasks are comprehensive (QA, reasoning, multi-turn coherence) and results in the paper provide baseline comparisons.
Cons: It’s relatively niche and complex – only 10 conversation scenarios (though each is long, providing many evaluation points). Setting up evaluation might be more involved, especially multimodal (you need to handle image inputs and interpret outputs). The conversations are synthetic (albeit refined by humans), so some quirks of real human dialogue might not be present. Also, evaluating open-ended dialogue coherence can be subjective; LoCoMo provides structured ways (like the event graph) but it might not capture everything.
Use when: You are building a chatbot or agent that needs long-term memory – for example, customer support agents handling lengthy threads, AI companions, or any system with memory beyond a single session. If you plan to use retrieval to fetch relevant pieces of past conversation (or knowledge base info) during dialogue, test on LoCoMo to see if it truly improves accuracy and reduces contradictions. It’s also a good stress test for any memory augmentation strategy: whether it’s RAG, a long context window, or hierarchical summarization, LoCoMo can reveal failure modes (forgetting facts, getting timeline wrong, etc.) in very extended conversations.
RAGTruth – Hallucination Annotation Benchmark
What it is: RAGTruth is a large-scale dataset (from early 2024) for evaluating hallucinations in RAG-generated outputs. Unlike other benchmarks that have Q&A pairs or tasks, RAGTruth is a corpus of model responses along with meticulous human annotations of hallucinated content. Specifically, it contains ~18,000 responses generated by various LLMs in a RAG setting, across several domains and tasks. Each response is annotated at the word level: human labelers marked which portions are unsupported by the retrieved documents (hallucinated), with tags indicating the type/severity of hallucination. The dataset covers multiple tasks (likely QA, summarization, knowledge-grounded generation) and multiple base LLMs, to provide a broad testbed for hallucination analysis. Essentially, it’s a benchmarking dataset for hallucination detection and calibration in RAG outputs.
What it evaluates: Hallucination propensity and detection. You can use RAGTruth in two main ways: (1) To evaluate generative models – run your RAG system on the same inputs and compare its outputs to the RAGTruth annotations to see how many hallucinated tokens it produces. E.g., measure the hallucination rate or an F1 against the “non-hallucinated spans.” (2) To train or evaluate hallucination detectors – models that input a response and its retrieved context and output which words or sentences are unsupported. RAGTruth provides a gold standard for such detectors. The original paper uses it to benchmark a variety of hallucination detection methods (like LLM-based judges, NLI models, etc.). The authors also fine-tuned a smaller model on RAGTruth that can predict hallucinations at word-level, achieving performance close to GPT-4 judgment. So, evaluation metrics involve precision/recall on hallucinated spans, hallucination frequency counts for a model, and so on. Because annotations include intensity/meta-info (like “trivial irrelevance” vs “critical unsupported claim”), one can also calculate metrics weighted by severity.
Format & Data: The data is released via GitHub and includes JSONL files with each response and annotations. Each entry contains the model’s response, the reference context (source text that was retrieved), and a list of labeled spans in the response that are hallucinations. Labels indicate the type (e.g. “Evident Baseless Info” meaning clearly made-up content). The data covers domains like Wikipedia QA, knowledge-grounded dialogue, etc. To evaluate a new model, you ideally use the same prompts and documents so you can compare outputs; or, if using different contexts, you’d need humans to re-annotate, which is outside the scope. The repository provides training code and even a finetuned hallucination detection model (so you can use their model to evaluate your outputs if you trust it) .
Pros: This is a gold mine for studying hallucinations. It’s large and diverse, and the word-level annotations mean you get very granular insight (not just “hallucinated or not”, but exactly what was hallucinated). It’s extremely useful for evaluating improvements in faithfulness: say you add a new prompting technique to reduce hallucinations – RAGTruth can quantify the improvement by exact measurement of hallucinated words. It’s also great for training your own classifier or reward model to penalize hallucinations. The fact that it covers multiple models and tasks makes it a robust reference – you can see how your model stacks up against, say, GPT-3 or others in terms of hallucination frequency on the same inputs.
Cons: It’s not a traditional end-to-end benchmark with a single accuracy score – you need to define what you measure (e.g. hallucination rate, span F1) and ensure you run your model on the same contexts. Also, it requires that the model’s outputs be aligned to the provided context documents to judge hallucination – if your system retrieves differently, the annotations might not directly apply. In practice, one might take the RAGTruth responses themselves as prompts (i.e., simulate the same scenario) to evaluate another model’s output. This is a bit involved. Additionally, focusing only on hallucinations doesn’t measure other aspects (like overall answer accuracy). It’s a narrow but deep benchmark.
Use when: Hallucination is your primary concern. For example, if you’re developing a RAG system for a domain where factual correctness is critical (legal, medical, etc.), use RAGTruth to benchmark how often the system strays from the provided sources. It’s particularly useful if you have a new hallucination mitigation strategy – you can test it on this standardized corpus. Also, if you want to build a detection tool (like a “fact-checker” that highlights unsupported sentences in the output), RAGTruth is a ready-made training and evaluation set. Essentially, it’s the go-to for measuring faithfulness in a fine-grained way, complementing other benchmarks that might only flag obvious failures. As an example, you might report: “On RAGTruth, our model reduced hallucinated tokens by 30% compared to baseline”, which is a powerful claim backed by this benchmark.
Tools & Frameworks for RAG Evaluation
In addition to datasets, there are evaluation toolkits that provide metrics, automation, and sometimes synthetic data to evaluate RAG systems. These are often model-agnostic libraries that you can plug your RAG pipeline into.
RAGAS – Retrieval-Augmented Generation Assessment Suite
What it is: RAGAS is an open-source library (“RAG As Service” or “RAG Assessment”) that provides a suite of evaluation metrics and tools for RAG pipelines. It’s designed to help developers “supercharge the evaluation” of LLM applications. RAGAS focuses on two main capabilities: (1) Computing a set of RAG-specific metrics given your model’s questions, retrieved context, and answers; and (2) Synthetic test data generation, i.e. automatically creating Q&A pairs from your documents to evaluate coverage. It essentially wraps a bunch of best-practice metrics into a single toolkit.
Metrics provided: RAGAS includes nine metrics covering both retrieval and generation. Key ones highlighted:
Faithfulness – factual consistency of the answer against the retrieved context. Uses an LLM-as-a-judge approach (prompting GPT-3.5/4 to verify if answer’s claims are supported). A high faithfulness score means no hallucinations relative to provided sources.
Answer Similarity – semantic similarity between the generated answer and a ground-truth answer, computed via embeddings (cosine similarity). This is akin to correctness if a reference answer is available.
Answer Relevancy – how relevant the answer is to the question. Implemented by generating variations of the question from the answer and checking similarity to the original question (a clever heuristic to catch if the answer actually addresses the query).
Answer Correctness – an overall score combining factual consistency and semantic similarity to the ground truth. This is meant to reflect if the answer is both correct in content and grounded.
Additionally, RAGAS documentation mentions metrics like Context Recall (did the retrieved documents contain the needed info?), Context Precision (were retrieved docs mostly relevant) etc., similar to the metrics in DeepEval below. Those help tune the retriever (e.g. is top-k too high, pulling in irrelevant text?). These metrics align with industry needs: “Is the answer correct? Is it using the sources? Are the sources good?”.
Tooling & Format: RAGAS is available as a Python package (pip install ragas). You input a set of quadruples: {question, retrieved documents, model answer, (optional) ground-truth answer}. It will output the metric scores. If you don’t have ground-truth answers (like in production user queries), you can still use metrics like faithfulness and relevancy which don’t require a reference. RAGAS also has a synthetic data generator that takes your corpus and uses an LLM to generate plausible question-answer pairs about it. This can bootstrap an evaluation set when you have none. The synthetic QAs are diverse (they cite a paper on diversity of generated queries). Documentation (docs.ragas.io) and examples are provided, and it’s pretty easy to integrate with tools like LangChain or LlamaIndex (which can produce the needed data logs).
Pros: Very easy to use – as noted, you can get metrics in ~5 lines of code. It’s great for continuous evaluation/CI: you can run RAGAS metrics on new deployments to catch regressions (e.g. if faithfulness drops, you introduced a bug). The metrics cover multiple dimensions, giving a more nuanced view than a single accuracy number. The synthetic data generation is a standout feature – it addresses the cold-start problem of evals (no labeled data) by creating a test set for you. Also, RAGAS leverages strong LLMs (GPT-4, etc.) under the hood for judging, which, while cost-incurring, means the eval is high-quality. It integrates well with vector DB pipelines, and can even output a combined score for your RAG (some users treat a weighted sum of these metrics as an overall “RAG score”). Another pro: RAGAS is actively maintained (it’s popular in the community, with many stars on GitHub) and has blog tutorials from practitioners.
Cons: Because some metrics use LLMs (for faithfulness, generating questions, etc.), running RAGAS can be slow or costly for large eval sets. However, you can configure which metrics to run to mitigate this. The reliability of certain metrics like answer relevancy or correctness is only as good as the prompting and models used – they may not perfectly align with human judgment in all cases (though they were inspired by research). Another con: metrics like answer similarity require a ground-truth answer, which you might not have for real user queries; in those cases you rely on proxy metrics (faithfulness, relevancy) which tell you about quality but not absolute correctness. Also, synthetic data generation, while useful, might produce some unrealistic questions – it’s recommended to have a human review the generated set (they mention it can be used as-is or edited by a human). In short, you get a lot of numbers – interpreting them requires some care (e.g. a high faithfulness score doesn’t mean the answer is correct, just that nothing clearly contradictory was said).
Use when: You want an all-in-one evaluation toolkit to integrate into your development cycle. If you’re building a RAG app (say a docs Q&A bot or a customer support assistant), RAGAS can be used to benchmark different retrievers, prompt templates, LLMs on your own data. It’s ideal for A/B testing: e.g., “Did switching to Hybrid search improve context relevance? What’s the faithfulness of Model A vs Model B on our domain questions?” It’s also great when you lack labeled test data – generate some via RAGAS and at least get a rough idea of performance (just be cautious treating synthetic eval as ground truth). RAGAS is most useful in non-academic, practical settings where you want to tune and monitor a RAG system’s quality continuously. For example, Vectara’s blog demonstrates using RAGAS metrics to evaluate their RAG pipeline on documentation QA. In summary, use RAGAS for quick, multifaceted evaluation of your RAG system on any data, especially to ensure faithfulness and relevance of responses.
“Open RAG Eval” (Vectara) – No-Golden-Answer Evaluation Framework
What it is: Open RAG Eval is an open-source RAG evaluation framework released by Vectara in 2025. (It’s sometimes informally called RAGEval by users.) Its goal is to let teams evaluate RAG systems without requiring predefined answers for each query. In other words, it emphasizes metrics that don’t need a ground-truth answer or human labeling, making evaluations easier and more scalable. Open RAG Eval implements the metrics developed in the TREC 2023 RAG Challenge, which was a large community evaluation of RAG systems. It uses LLM-based judging under the hood to score retrieval and generation quality. The framework is Apache-2.0 licensed and designed to work with any RAG pipeline (they provide a connector for their own platform, but you can hook it to others) .
Metrics provided: Two main families of metrics, paralleling the two halves of RAG:
Retrieval Metrics – UMBRELA: This stands for “Unsupervised Metric for Binary RELevence Assessment” (from the paper cited by Vectara). Essentially, an LLM is prompted to judge each retrieved passage’s relevance to the query on a 0–3 scale. The scale definitions are: 0 = not related, 1 = on-topic but doesn’t answer, 2 = partially answers, 3 = fully answers the query. By scoring each passage, you can derive metrics like average relevance, Precision@k, Recall@k, nDCG, etc., as if you had human relevance judgments. In Open RAG Eval, they typically report the average UMBRELA score per query or similar. The key: no human labels needed – these are generated by an LLM, yet they correlate well with manual judgments (as reported). So UMBRELA effectively evaluates how good your retrieval results were for supporting the question.
Generation Metrics – AutoNUGGET: Based on the AutoNugget approach, this metric measures how well the generated answer covers the key facts (nuggets) from the retrieved documents. It works in two steps: (1) Nugget Extraction: An LLM reads the retrieved passages and generates a list of atomic facts (“nuggets”) that should appear in a correct answer, marking each as vital or optional. (2) Nugget Matching: The LLM (or a script) then checks which of those nuggets appear in the system’s answer. From this we can compute scores like precision, recall of nuggets, weighted by vital vs okay. Open RAG Eval implements all the AutoNugget scores (there are variants that penalize missing vital nuggets more, etc.). In short, AutoNugget gauges coverage and correctness of the answer relative to the source facts. A high score means the answer included all the important info from the source and thus is likely correct and complete.
These metrics together address: Did we retrieve good info? Did the answer use that info correctly? They also mention possibly other minor metrics (e.g. language quality or an overall helpfulness score) but the core are UMBRELA and AutoNugget.
Tooling & Format: The toolkit is on GitHub (vectara/open-rag-eval). You can feed it either: a live RAG pipeline (via an API connector) or a static dataset of queries with retrieved passages and answers. The evaluation then produces a report per query with all the metric scores. It’s designed to be easy to use with enterprise data – e.g., connect to your production RAG system to continuously eval. Under the hood, it will call an LLM (likely GPT-4 by default) to do the UMBRELA and nugget scoring. They chose metrics validated by the TREC RAG competition (which had ~24 teams, 100+ runs), so there is some community endorsement that these metrics reflect human perceptions of quality. Documentation shows examples of how to run an end-to-end eval and interpret results.
Pros: No ground truth needed – this is huge if you don’t have human-written answers for your queries. You can evaluate on real user questions by just capturing what documents your system retrieved and what answer it gave, and let open-rag-eval score it. This enables large-scale evaluation at low cost (just the API calls) and even evaluation on proprietary or long-tail queries where labeling would be impossible. The metrics (UMBRELA, AutoNugget) are research-backed and were shown to correlate with human quality judgments, so you’re not flying blind. The framework is flexible: you can drop in other LLMs for judging if you want (maybe use an open-source LLM to avoid API costs, though quality might drop). It covers both retrieval and generation aspects clearly, helping diagnose where a problem lies (low UMBRELA but high nugget recall = retrieval is the bottleneck; vice versa might mean retrieval was fine but generation missed stuff or hallucinated). Another pro: since it’s associated with Vectara (who have a commercial RAG platform), it’s likely to be maintained and improved as a community tool.
Cons: Using LLMs as judges, while avoiding the need for golden answers, still incurs compute cost and potential variability. For instance, UMBRELA scoring every passage with GPT-4 for thousands of queries could be expensive (though you might use a cheaper model with some loss in fidelity). Also, while correlated with humans, an automated metric is not perfect – e.g., an answer might be correct but phrased differently and maybe the nugget matching could miss it (though nugget approach is quite robust to wording). Setup is a bit more complex than metrics like ROUGE: you need to have the pipeline outputs and possibly write a small script to interface if not using Vectara’s connector. Another consideration: open-rag-eval assumes the retrieved passages do contain the answer (if the answer is actually nowhere in the docs, AutoNugget might not penalize hallucination strongly because it can only check presence of facts that are in docs; however, UMBRELA would give low scores to those docs, indicating a retrieval miss). So to catch pure hallucination beyond provided facts, one might complement with a direct faithfulness check as well.
Use when: You have a RAG system in production or in development without a labeled QA dataset, and you want to compare configurations or monitor quality. It’s very useful for regression testing: e.g., if you update your index or retriever algorithm, do the UMBRELA scores improve? If you switch your LLM, does AutoNugget catch more missing facts in answers? It’s also great for benchmarking different RAG solutions on a custom set of queries – for example, run the same queries through Vendor A and Vendor B, use open-rag-eval to see which gives more relevant retrievals and more grounded answers. In summary, open-rag-eval is best when you need robust, automated evaluation of RAG in the absence of ground truth answers, focusing on relevance and faithfulness of both retrieved evidence and final answers.
DeepEval (Confident-AI) – LLM-Powered RAG Unit Testing
What it is: DeepEval is an open-source LLM evaluation framework by Confident AI (available on GitHub confident-ai/deepeval). It offers a range of metrics and an “opinionated framework for unit testing RAG applications”. DeepEval can evaluate chatbots, agents, and RAG pipelines, but here we focus on its RAG evaluation capabilities. It breaks evaluations into test cases and uses LLMs to power many of the checks. A key philosophy is evaluating retriever and generator separately to pinpoint failure modes. Confident AI’s blog post on RAG evaluation (July 2025) introduces DeepEval and provides code examples using it.
Metrics provided: DeepEval’s RAG metrics are very much in line with industry-standard ones (and indeed overlap with RAGAS’s definitions, likely convergent best practices). Five core metrics are highlighted:
Answer Relevancy: Does the model’s answer actually address the user’s question? DeepEval uses GPT-based scoring for this (similar to RAGAS’s method). An irrelevant or off-target answer gets a low score.
Faithfulness: Are the answer’s claims supported by the retrieved context, or is it hallucinating? This uses an LLM judge or NLI techniques to ensure all statements have evidence in the provided docs.
Contextual Relevancy: How relevant are the retrieved documents to the query? (Similar to UMBRELA/Precision). If your top-k retrieval pulled in off-topic text, this score drops.
Contextual Recall: Does the retrieved set contain the necessary information to answer the question? (This assumes a known answer or reference; DeepEval can use either an LLM to infer if the info is present or compare to a ground truth answer as needed.). Essentially, if something important was missing from the retrieval, recall is low.
Contextual Precision: Are the retrieved documents mostly on-topic and not filled with distracting info? This is like a measure of how focused the retrieval is. It can be evaluated by checking if top results are all relevant (could be derived from relevancy judgments as well).
DeepEval thus explicitly separates retriever performance (context relevancy/precision/recall) and generator performance (answer relevancy, faithfulness). It encourages evaluating each component independently to see where things go wrong. It even suggests incorporating these evals in CI pipelines (so every time you update code, DeepEval tests run on a suite of queries).
Tooling & Format: DeepEval can be installed via pip. You configure “eval tasks” by writing small Python test scripts, or even YAML configs, specifying the model to use for judging and the prompts. The Confident AI blog gives examples where in just a few lines you evaluate a RAG pipeline’s precision/recall by feeding it queries and comparing retrievals to a reference. It supports custom prompts, meaning you can adjust how the LLM judge is asked (important for things like faithfulness to reduce false positives). It’s more of a framework than a fixed script – meaning it might require a bit of coding to integrate, but it’s flexible. For instance, you could use DeepEval to generate a detailed evaluation report per query or to run a suite of canned questions as unit tests (pass/fail criteria can be set, like “precision must be > X” etc.). Integration with tools like Milvus and LlamaIndex is documented.
Pros: DeepEval is built with developer workflow in mind – treat evals like tests. This encourages frequent testing and catching issues early (like if a code change hurts retrieval relevancy, DeepEval would flag it). The metrics cover all basic aspects one should care about in RAG, and they are modular. The strong focus on component-level evaluation is a pro: it helps answer “is my search failing or is the LLM screwing up?” clearly. Another pro: it’s open-source and quite popular (Confident AI’s tools have many users), so there’s community support. The blog claims it allows SOTA metrics in 5 lines of code, which underlines ease of use. You can also extend it – if you want to add a custom metric or use a specific LLM or NLI model for evaluation, you can plug that in. The fact that it aligns with “industry standard metrics” means it’s easy to interpret results and communicate them.
Cons: As with RAGAS and open-rag-eval, LLM-based evaluation costs money and can be slow, but that’s a trade-off for richer metrics. DeepEval’s reliance on GPT judges (Confident AI often uses GPT-4 or similar for their evals) means you need API access and must handle possible judge errors (they reported GPT-based judges can be ~10–20% incorrect, so not infallible). Another con: no leaderboards or datasets built-in – it’s a framework, so you supply the data (which in practice is fine, since you likely have your own test queries or use some of the benchmarks above). Some initial setup is needed to integrate with your pipeline outputs. Also, while unit-test style is great for devs, some may find it a bit code-heavy compared to one-click script; it’s powerful, but you need to decide on which queries to test, what thresholds to set, etc. This makes it very flexible but not as turnkey as a fixed benchmark.
Use when: You are in active development of a RAG system and want to continuously evaluate it. DeepEval is ideal for CI/CD pipelines or nightly runs where you ensure your RAG’s quality doesn’t regress. For example, you might have 50 representative questions that you always test – DeepEval will give you precision/recall/faithfulness on them after each change. Use it when you need granular insight: if a metric drops, you immediately know if it’s retrieval or generation that’s the culprit. It’s also useful when you want to experiment with evaluation metrics themselves – e.g. try an NLI model vs. GPT-4 for faithfulness scoring – DeepEval provides that playground. In short, if you view evaluation as part of your development cycle (and not just a one-time leaderboard score), DeepEval is a great choice to incorporate RAG evaluation as code. As Confident AI says, “RAG pipelines can fail in many ways… use retriever-targeted and generator-targeted metrics to find the failure” – DeepEval is built exactly for that philosophy.
(Also noteworthy: OpenAI Evals)
OpenAI’s Evals framework deserves a brief mention. It’s an open-source evaluation harness where you can define custom evals and run them against OpenAI models. While not specialized for RAG, one can incorporate retrieval in the eval loop. There isn’t an “official OpenAI RAG benchmark” per se, but OpenAI Evals includes some question-answering evals and allows tools usage in evaluations. For instance, you could use it to evaluate a GPT-4 with browsing vs. without on some questions. However, the frameworks above (RAGAS, DeepEval, etc.) are more tailored to RAG specifics. OpenAI Evals is more general and requires more setup (writing Python eval scripts). It’s powerful for crowd-sourced benchmark contributions and comparing models on tasks (and was used to evaluate GPT-4), but for most RAG evaluation needs, the specialized tools and benchmarks we covered will be more directly applicable.
Recommendations: If you have a known benchmark dataset in your domain, use those first for an objective accuracy measure (e.g. STaRK for product search, CRAG for general QA, FreshQA for recency). Then incorporate an ongoing eval tool like RAGAS or DeepEval in your development loop for continuous feedback on retrieval relevance and answer faithfulness. For catching hallucinations, RAGTruth or at least a faithfulness metric (RAGAS/DeepEval) is essential – a high answer accuracy means little if faithfulness is low, as the user might get correct answers on easy questions but misinformation on others. Use Open RAG Eval if you want to evaluate on real queries where creating gold answers is impractical – it gives a reliable proxy for quality. And if long conversations or adaptive behaviors are part of your system, specialized benchmarks like LoCoMo and RetrievalQA will ensure you don’t overlook those challenging aspects.
By combining these benchmarks and tools, you can achieve a comprehensive evaluation of a RAG system: from retrieval recall, through answer correctness and coverage, to hallucination detection and even long-term memory. Each benchmark/framework above shines in a particular scenario – pick the ones that match your system’s use-case and failure modes for the best insights.
Sources: Benchmarks and metrics as described in STaRK, CRAG, KILT, FreshQA, RetrievalQA, LoCoMo, RAGTruth. RAGAS metrics from Vectara/Confident AI, Open RAG Eval metrics from Vectara, DeepEval approach from Confident AI, and community discussions. All tools and benchmarks are open-source as of 2025.